V4:Tutorial B6 Breaking AES (Manual CPA Attack)
| B6: Breaking AES (Manual CPA Attack) | |
|---|---|
| Target Architecture | XMEGA/Arm/Other |
| Hardware Crypto | No |
| Software Release | V3 / V4 / V5 |
This tutorial will demonstrate how to perform a CPA attack using a simple Python script. This will bring you through an entire CPA attack without using the ChipWhisperer Analyzer program, which will greatly improve your understanding of the actual attack method.
The CPA Attack Theory
As a background on the CPA attack, please see the section Correlation Power Analysis. It's assumed you've read that section and come back to this. Ok, you've done that? Good let's continue.
Assuming you actually read that, it should be apparent that there is a few things we need to accomplish:
- Reading the data, which consists of the analog waveform (trace) and input text sent to the encryption core
- Making the power leakage model, where it takes a known input text along with a guess of the key byte
- Implementing the correlation equation, and then looping through all the traces
- Ranking the output of the correlation equation to determine the most likely key
Setting Up the Project
It is assumed you are experienced with Python development, or have at least run a Python program! If you are on Windows you'll probably use IDLE as a code editor, although you can use any code editor you wish.
Initially, we'll be using Python interactively. This means to just run python at the command prompt, and enter commands into the window. Later we'll move onto writing a simple script which executes these commands.
Note if you want to use matplotlib, and are running a native Python installation, you may need to install that package. If the import matplotlib command listed in the next section fails, you'll need to install these, which again for Windows you can get from the Pre-Built Windows Binaries
Exploring the Trace Data
The next step is to read the trace data. If you don't have any data yet, you should follow the steps in Tutorial B5 Breaking AES (Straightforward) to record some traces.
You need to find the source trace files, which have a .npy extension. You can follow the path of a .cwp (ChipWhisperer Project) file to find the associated trace .cfg file. The same directory as the .cfg file will have the .npy files. As an example, say that our .cwp file contains this line:
[Trace Management] tracefile0 = default-data-dir\traces\config_2013.11.18-16.40.58_.cfg
Opening the .cfg file shows the prefix= line, which tells us the name of the data files:
[Trace Config] numTraces = 50 format = native numPoints = 3000 prefix = 2013.11.18-16.40.58_
This means our trace file is in default-data-dir\traces\2013.11.18-16.40.58_traces.npy and the plaintext is in default-data-dir\traces\2013.11.18-16.40.58_textin.npy.
Using default installs, this directory will be C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces. Let's assume you've run a capture and have 50 traces of our usual AVR target.
To read them, first import NumPy to your Python console, and optionally matplotlib (not needed but useful to visualize):
>>> import numpy as np >>> import matplotlib.pyplot as plt
Then use np.load as such (note: the r infront of the string means you don't need to escape slahes
>>> traces = np.load(r'C:chipwhisperersoftwarechipwhisperercapturedefault-data-dirtraces2013.11.18-16.40.58_traces.npy') >>> pt = np.load(r'C:chipwhisperersoftwarechipwhisperercapturedefault-data-dirtraces2013.11.18-16.40.58_textin.npy')
You can print, for example, the first plaintext sent to the device:
>>> pt[0] array([ 63, 3, 80, 100, 21, 236, 26, 68, 88, 177, 135, 226, 198, 205, 26, 133], dtype=uint8)
Or check the size of the power traces:
>>> np.shape(traces) (51, 3000) >>> np.shape(traces[0]) (3000,)
And finally plot a single power trace:
>>> plt.plot(traces[0]) [<matplotlib.lines.Line2D object at 0x05EF3CF0>] >>> plt.show()
After executing plt.show() you should get a window to pop up with the single power trace.
Reading the Trace Data in a Script
Enough fooling around. Now let's make a script that loads the trace and tries to step through them. Make a new file called for example simplecpa.py, starting with this simple example:
import numpy as np
traces = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_traces.npy')
pt = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_textin.npy')
numtraces = np.shape(traces)[0]
numpoint = np.shape(traces)[1]
#Use less than the maximum traces by setting numtraces to something
#numtraces = 15
#Set 16 to something lower (like 1) to only go through a single subkey
for bnum in range(0, 16):
for tnum in range(0, numtraces):
print "Subkey %d, trace %d"%(bnum, tnum)
If you run this script, it will generate the following output:
Subkey 0, trace 0
Subkey 0, trace 1
Subkey 0, trace 2
Subkey 0, trace 3
Subkey 0, trace 4
Subkey 0, trace 5
Subkey 0, trace 6
Subkey 0, trace 7
Subkey 0, trace 8
Subkey 0, trace 9
Subkey 0, trace 10
... tons more lines ...
Subkey 15, trace 45
Subkey 15, trace 46
Subkey 15, trace 47
Subkey 15, trace 48
Subkey 15, trace 49
Subkey 15, trace 50
It's looping through a single subkey at a time, then looping through every trace. Let's limit it to break a single subkey. Do this by changing the line for bnum in range(0, 16): to for bnum in range(0, 1):. We'll go back later to breaking the whole thing. That part of the file now looks like:
#Set 16 to something lower (like 1) to only go through a single subkey
for bnum in range(0, 1):
for tnum in range(0, numtraces):
print "Subkey %d, trace %d"%(bnum, tnum)
Performing the Guess
Next, we need to guess every possibility for the subkey. This is done with another loop - we'll first remove the loop going through each trace, and simply loop through each hypothetical value for each subkey:
#Set 16 to something lower (like 1) to only go through a single subkey
for bnum in range(0, 16):
cpaoutput = [0]*256
for kguess in range(0, 256):
print "Subkey %d, hyp = %02x"%(bnum, kguess)
Note if you want to simplify your life, you can guess only keys around the known answer initially. For example if we know the first byte of the key is 0x2B, we can do:
for kguess in range(0x26, 0x2F):
print "Subkey %d, hyp = %02x"%(bnum, kguess)
Note that in Python we can specify hex constants directly! Now the system will only be searching from 0x26 - 0x2F for the correct key. Once we have a guess, we need to calculate the intermediate value corresponding to the guess.
Looking way back to how AES works, remember we are effectively attemping to target the position at the bottom of this figure:
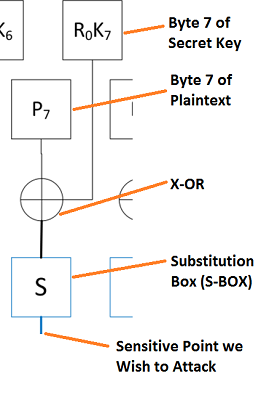 The AES algorithm involves a number of rounds, this is a detail from the first round of operation. Each input byte is XOR'd with a byte of the (unknown) secret key. This is passed through an S-Box, which is simply a look-up table. The output of this S-Box is what we'll use to 'check' our guessed value of the key.
The AES algorithm involves a number of rounds, this is a detail from the first round of operation. Each input byte is XOR'd with a byte of the (unknown) secret key. This is passed through an S-Box, which is simply a look-up table. The output of this S-Box is what we'll use to 'check' our guessed value of the key.

The objective is thus to determine the output of the S-Box, where the S-Box is defined as follows:
sbox=(
0x63,0x7c,0x77,0x7b,0xf2,0x6b,0x6f,0xc5,0x30,0x01,0x67,0x2b,0xfe,0xd7,0xab,0x76,
0xca,0x82,0xc9,0x7d,0xfa,0x59,0x47,0xf0,0xad,0xd4,0xa2,0xaf,0x9c,0xa4,0x72,0xc0,
0xb7,0xfd,0x93,0x26,0x36,0x3f,0xf7,0xcc,0x34,0xa5,0xe5,0xf1,0x71,0xd8,0x31,0x15,
0x04,0xc7,0x23,0xc3,0x18,0x96,0x05,0x9a,0x07,0x12,0x80,0xe2,0xeb,0x27,0xb2,0x75,
0x09,0x83,0x2c,0x1a,0x1b,0x6e,0x5a,0xa0,0x52,0x3b,0xd6,0xb3,0x29,0xe3,0x2f,0x84,
0x53,0xd1,0x00,0xed,0x20,0xfc,0xb1,0x5b,0x6a,0xcb,0xbe,0x39,0x4a,0x4c,0x58,0xcf,
0xd0,0xef,0xaa,0xfb,0x43,0x4d,0x33,0x85,0x45,0xf9,0x02,0x7f,0x50,0x3c,0x9f,0xa8,
0x51,0xa3,0x40,0x8f,0x92,0x9d,0x38,0xf5,0xbc,0xb6,0xda,0x21,0x10,0xff,0xf3,0xd2,
0xcd,0x0c,0x13,0xec,0x5f,0x97,0x44,0x17,0xc4,0xa7,0x7e,0x3d,0x64,0x5d,0x19,0x73,
0x60,0x81,0x4f,0xdc,0x22,0x2a,0x90,0x88,0x46,0xee,0xb8,0x14,0xde,0x5e,0x0b,0xdb,
0xe0,0x32,0x3a,0x0a,0x49,0x06,0x24,0x5c,0xc2,0xd3,0xac,0x62,0x91,0x95,0xe4,0x79,
0xe7,0xc8,0x37,0x6d,0x8d,0xd5,0x4e,0xa9,0x6c,0x56,0xf4,0xea,0x65,0x7a,0xae,0x08,
0xba,0x78,0x25,0x2e,0x1c,0xa6,0xb4,0xc6,0xe8,0xdd,0x74,0x1f,0x4b,0xbd,0x8b,0x8a,
0x70,0x3e,0xb5,0x66,0x48,0x03,0xf6,0x0e,0x61,0x35,0x57,0xb9,0x86,0xc1,0x1d,0x9e,
0xe1,0xf8,0x98,0x11,0x69,0xd9,0x8e,0x94,0x9b,0x1e,0x87,0xe9,0xce,0x55,0x28,0xdf,
0x8c,0xa1,0x89,0x0d,0xbf,0xe6,0x42,0x68,0x41,0x99,0x2d,0x0f,0xb0,0x54,0xbb,0x16)
Thus we need to write a function taking a single byte of input, a single byte of the guessed key, and return the output of the S-Box:
def intermediate(pt, keyguess):
return sbox[pt ^ keyguess]
Finally, remember we want the Hamming Weight of the guess. Our assumption is that the system is leaking the Hamming Weight of the output of that S-Box. As a dumb solution, we could first convert every number to binary and count the 1's:
>>> bin(0x1F)
'0b11111'
>>> bin(0x1F).count('1')
5
This will ultimately be fairly slow. Instead we make a lookup table using this idea:
>>> HW = [bin(n).count("1") for n in range(0,256)]
>>> HW
[0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8]
And finally can create our complete intermediate value and power model functions:
HW = [bin(n).count("1") for n in range(0,256)]
sbox=(
0x63,0x7c,0x77,0x7b,0xf2,0x6b,0x6f,0xc5,0x30,0x01,0x67,0x2b,0xfe,0xd7,0xab,0x76,
0xca,0x82,0xc9,0x7d,0xfa,0x59,0x47,0xf0,0xad,0xd4,0xa2,0xaf,0x9c,0xa4,0x72,0xc0,
0xb7,0xfd,0x93,0x26,0x36,0x3f,0xf7,0xcc,0x34,0xa5,0xe5,0xf1,0x71,0xd8,0x31,0x15,
0x04,0xc7,0x23,0xc3,0x18,0x96,0x05,0x9a,0x07,0x12,0x80,0xe2,0xeb,0x27,0xb2,0x75,
0x09,0x83,0x2c,0x1a,0x1b,0x6e,0x5a,0xa0,0x52,0x3b,0xd6,0xb3,0x29,0xe3,0x2f,0x84,
0x53,0xd1,0x00,0xed,0x20,0xfc,0xb1,0x5b,0x6a,0xcb,0xbe,0x39,0x4a,0x4c,0x58,0xcf,
0xd0,0xef,0xaa,0xfb,0x43,0x4d,0x33,0x85,0x45,0xf9,0x02,0x7f,0x50,0x3c,0x9f,0xa8,
0x51,0xa3,0x40,0x8f,0x92,0x9d,0x38,0xf5,0xbc,0xb6,0xda,0x21,0x10,0xff,0xf3,0xd2,
0xcd,0x0c,0x13,0xec,0x5f,0x97,0x44,0x17,0xc4,0xa7,0x7e,0x3d,0x64,0x5d,0x19,0x73,
0x60,0x81,0x4f,0xdc,0x22,0x2a,0x90,0x88,0x46,0xee,0xb8,0x14,0xde,0x5e,0x0b,0xdb,
0xe0,0x32,0x3a,0x0a,0x49,0x06,0x24,0x5c,0xc2,0xd3,0xac,0x62,0x91,0x95,0xe4,0x79,
0xe7,0xc8,0x37,0x6d,0x8d,0xd5,0x4e,0xa9,0x6c,0x56,0xf4,0xea,0x65,0x7a,0xae,0x08,
0xba,0x78,0x25,0x2e,0x1c,0xa6,0xb4,0xc6,0xe8,0xdd,0x74,0x1f,0x4b,0xbd,0x8b,0x8a,
0x70,0x3e,0xb5,0x66,0x48,0x03,0xf6,0x0e,0x61,0x35,0x57,0xb9,0x86,0xc1,0x1d,0x9e,
0xe1,0xf8,0x98,0x11,0x69,0xd9,0x8e,0x94,0x9b,0x1e,0x87,0xe9,0xce,0x55,0x28,0xdf,
0x8c,0xa1,0x89,0x0d,0xbf,0xe6,0x42,0x68,0x41,0x99,0x2d,0x0f,0xb0,0x54,0xbb,0x16)
def intermediate(pt, keyguess):
return sbox[pt ^ keyguess]
Which we can insert into the guessing routine, such that our complete file now looks like this:
import numpy as np
HW = [bin(n).count("1") for n in range(0,256)]
sbox=(
0x63,0x7c,0x77,0x7b,0xf2,0x6b,0x6f,0xc5,0x30,0x01,0x67,0x2b,0xfe,0xd7,0xab,0x76,
0xca,0x82,0xc9,0x7d,0xfa,0x59,0x47,0xf0,0xad,0xd4,0xa2,0xaf,0x9c,0xa4,0x72,0xc0,
0xb7,0xfd,0x93,0x26,0x36,0x3f,0xf7,0xcc,0x34,0xa5,0xe5,0xf1,0x71,0xd8,0x31,0x15,
0x04,0xc7,0x23,0xc3,0x18,0x96,0x05,0x9a,0x07,0x12,0x80,0xe2,0xeb,0x27,0xb2,0x75,
0x09,0x83,0x2c,0x1a,0x1b,0x6e,0x5a,0xa0,0x52,0x3b,0xd6,0xb3,0x29,0xe3,0x2f,0x84,
0x53,0xd1,0x00,0xed,0x20,0xfc,0xb1,0x5b,0x6a,0xcb,0xbe,0x39,0x4a,0x4c,0x58,0xcf,
0xd0,0xef,0xaa,0xfb,0x43,0x4d,0x33,0x85,0x45,0xf9,0x02,0x7f,0x50,0x3c,0x9f,0xa8,
0x51,0xa3,0x40,0x8f,0x92,0x9d,0x38,0xf5,0xbc,0xb6,0xda,0x21,0x10,0xff,0xf3,0xd2,
0xcd,0x0c,0x13,0xec,0x5f,0x97,0x44,0x17,0xc4,0xa7,0x7e,0x3d,0x64,0x5d,0x19,0x73,
0x60,0x81,0x4f,0xdc,0x22,0x2a,0x90,0x88,0x46,0xee,0xb8,0x14,0xde,0x5e,0x0b,0xdb,
0xe0,0x32,0x3a,0x0a,0x49,0x06,0x24,0x5c,0xc2,0xd3,0xac,0x62,0x91,0x95,0xe4,0x79,
0xe7,0xc8,0x37,0x6d,0x8d,0xd5,0x4e,0xa9,0x6c,0x56,0xf4,0xea,0x65,0x7a,0xae,0x08,
0xba,0x78,0x25,0x2e,0x1c,0xa6,0xb4,0xc6,0xe8,0xdd,0x74,0x1f,0x4b,0xbd,0x8b,0x8a,
0x70,0x3e,0xb5,0x66,0x48,0x03,0xf6,0x0e,0x61,0x35,0x57,0xb9,0x86,0xc1,0x1d,0x9e,
0xe1,0xf8,0x98,0x11,0x69,0xd9,0x8e,0x94,0x9b,0x1e,0x87,0xe9,0xce,0x55,0x28,0xdf,
0x8c,0xa1,0x89,0x0d,0xbf,0xe6,0x42,0x68,0x41,0x99,0x2d,0x0f,0xb0,0x54,0xbb,0x16)
def intermediate(pt, keyguess):
return sbox[pt ^ keyguess]
traces = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_traces.npy')
pt = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_textin.npy')
numtraces = np.shape(traces)[0]
numpoint = np.shape(traces)[1]
#Use less than the maximum traces by setting numtraces to something
#numtraces = 15
for bnum in range(0, 16):
cpaoutput = [0]*256
for kguess in range(0, 256):
print "Subkey %d, hyp = %02x"%(bnum, kguess)
for tnum in range(0, numtraces):
hypint = HW[intermediate(pt[tnum][bnum], kguess)]
Performing the Check
Remember the objective is to calculate the following:
![{r_{i,j}} = \frac{{\sum\nolimits_{d = 1}^D {\left[ {\left( {{h_{d,i}} - \overline {{h_i}} } \right)\left( {{t_{d,j}} - \overline {{t_j}} } \right)} \right]} }}{{\sqrt {\sum\nolimits_{d = 1}^D {{{\left( {{h_{d,i}} - \overline {{h_i}} } \right)}^2}} \sum\nolimits_{d = 1}^D {{{\left( {{t_{d,j}} - \overline {{t_j}} } \right)}^2}} } }}](/images/math/4/3/e/x43ec93b3925401eb381eff776aef625e.png.pagespeed.ic.CDstywW1XH.png)
Where the following is the association between variable names in the equation and our python script:
| Equation | Python Variable |
|---|---|
| d | tnum |
| i | kguess |
| j | j index trace point, e.g.: traces[tnum][j] |
| h | hypint |
| t | traces |
It can be noticed there is effectively three sums, all sums are done over all traces. For this initial implementation we'll be explicitly calculating some of these sums, although it's faster to use NumPy to calculate across large arrays. We'll convert the equation into this format:

Let's go ahead an implement this in Python. To begin with, we initialize those three sums to zero:
#Initialize arrays & variables to zero sumnum = np.zeros(numpoint) sumden1 = np.zeros(numpoint) sumden2 = np.zeros(numpoint)
Next, let's save those hypothetical values for each associated plaintext with the current guess. Remember we are going to compare every guess to all traces. We modify our loop-over-every-trace syntax from before to append these values to a new list:
hyp = np.zeros(numtraces)
for tnum in range(0, numtraces):
hyp[tnum] = HW[intermediate(pt[tnum][bnum], kguess)]
Next, we need to calculate the mean of the hypothesis, 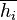 . This is done via NumPy:
. This is done via NumPy:
#Mean of hypothesis meanh = np.mean(hyp, dtype=np.float64)
Similiarly for the mean of all traces, 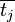 . Remember we want the output to be a 1 x numpoint size array:
. Remember we want the output to be a 1 x numpoint size array:
#Mean of all points in trace meant = np.mean(traces, axis=0, dtype=np.float64)
Next, let's again consider the three sums to be implemented:
![sumnum = {\sum\nolimits_{d = 1}^D {\left[ {\left( {{h_{d,i}} - \overline {{h_i}} } \right)\left( {{t_{d,j}} - \overline {{t_j}} } \right)} \right]} }](/images/math/a/6/7/a67339d7b5fc5b53496253f7b67b6919.png)


Note there is some common terms in all three of these, along with a common summation index. We can thus implement them as follows:
#For each trace, do the following
for tnum in range(numtraces):
hdiff = (hyp[tnum] - meanh)
tdiff = traces[tnum,:] - meant
sumnum = sumnum + (hdiff*tdiff)
sumden1 = sumden1 + hdiff*hdiff
sumden2 = sumden2 + tdiff*tdiff
The size of sumnum, sumden1, and sumden2 are all 1 x numpoints, meaning an output is generated for each point of the input. Note each of these is calculated independantly, thus we simply avoid looping through every point by using the vector notation of NumPy. Finally, we calculate the single output vector & save it as a specific key guess:
cpaoutput[kguess] = sumnum / np.sqrt( sumden1 * sumden2 )
Tying it all together, we end up with the following:
import numpy as np
HW = [bin(n).count("1") for n in range(0,256)]
sbox=(
0x63,0x7c,0x77,0x7b,0xf2,0x6b,0x6f,0xc5,0x30,0x01,0x67,0x2b,0xfe,0xd7,0xab,0x76,
0xca,0x82,0xc9,0x7d,0xfa,0x59,0x47,0xf0,0xad,0xd4,0xa2,0xaf,0x9c,0xa4,0x72,0xc0,
0xb7,0xfd,0x93,0x26,0x36,0x3f,0xf7,0xcc,0x34,0xa5,0xe5,0xf1,0x71,0xd8,0x31,0x15,
0x04,0xc7,0x23,0xc3,0x18,0x96,0x05,0x9a,0x07,0x12,0x80,0xe2,0xeb,0x27,0xb2,0x75,
0x09,0x83,0x2c,0x1a,0x1b,0x6e,0x5a,0xa0,0x52,0x3b,0xd6,0xb3,0x29,0xe3,0x2f,0x84,
0x53,0xd1,0x00,0xed,0x20,0xfc,0xb1,0x5b,0x6a,0xcb,0xbe,0x39,0x4a,0x4c,0x58,0xcf,
0xd0,0xef,0xaa,0xfb,0x43,0x4d,0x33,0x85,0x45,0xf9,0x02,0x7f,0x50,0x3c,0x9f,0xa8,
0x51,0xa3,0x40,0x8f,0x92,0x9d,0x38,0xf5,0xbc,0xb6,0xda,0x21,0x10,0xff,0xf3,0xd2,
0xcd,0x0c,0x13,0xec,0x5f,0x97,0x44,0x17,0xc4,0xa7,0x7e,0x3d,0x64,0x5d,0x19,0x73,
0x60,0x81,0x4f,0xdc,0x22,0x2a,0x90,0x88,0x46,0xee,0xb8,0x14,0xde,0x5e,0x0b,0xdb,
0xe0,0x32,0x3a,0x0a,0x49,0x06,0x24,0x5c,0xc2,0xd3,0xac,0x62,0x91,0x95,0xe4,0x79,
0xe7,0xc8,0x37,0x6d,0x8d,0xd5,0x4e,0xa9,0x6c,0x56,0xf4,0xea,0x65,0x7a,0xae,0x08,
0xba,0x78,0x25,0x2e,0x1c,0xa6,0xb4,0xc6,0xe8,0xdd,0x74,0x1f,0x4b,0xbd,0x8b,0x8a,
0x70,0x3e,0xb5,0x66,0x48,0x03,0xf6,0x0e,0x61,0x35,0x57,0xb9,0x86,0xc1,0x1d,0x9e,
0xe1,0xf8,0x98,0x11,0x69,0xd9,0x8e,0x94,0x9b,0x1e,0x87,0xe9,0xce,0x55,0x28,0xdf,
0x8c,0xa1,0x89,0x0d,0xbf,0xe6,0x42,0x68,0x41,0x99,0x2d,0x0f,0xb0,0x54,0xbb,0x16)
def intermediate(pt, keyguess):
return sbox[pt ^ keyguess]
traces = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_traces.npy')
pt = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_textin.npy')
numtraces = np.shape(traces)[0]-1
numpoint = np.shape(traces)[1]
#Use less than the maximum traces by setting numtraces to something
#numtraces = 15
bestguess = [0]*16
#Set 16 to something lower (like 1) to only go through a single subkey & save time!
for bnum in range(0, 16):
cpaoutput = [0]*256
maxcpa = [0]*256
for kguess in range(0, 256):
print "Subkey %2d, hyp = %02x: "%(bnum, kguess),
#Initialize arrays & variables to zero
sumnum = np.zeros(numpoint)
sumden1 = np.zeros(numpoint)
sumden2 = np.zeros(numpoint)
hyp = np.zeros(numtraces)
for tnum in range(0, numtraces):
hyp[tnum] = HW[intermediate(pt[tnum][bnum], kguess)]
#Mean of hypothesis
meanh = np.mean(hyp, dtype=np.float64)
#Mean of all points in trace
meant = np.mean(traces, axis=0, dtype=np.float64)
#For each trace, do the following
for tnum in range(0, numtraces):
hdiff = (hyp[tnum] - meanh)
tdiff = traces[tnum,:] - meant
sumnum = sumnum + (hdiff*tdiff)
sumden1 = sumden1 + hdiff*hdiff
sumden2 = sumden2 + tdiff*tdiff
cpaoutput[kguess] = sumnum / np.sqrt( sumden1 * sumden2 )
maxcpa[kguess] = max(abs(cpaoutput[kguess]))
print maxcpa[kguess]
#Find maximum value of key
bestguess[bnum] = np.argmax(maxcpa)
print "Best Key Guess: "
for b in bestguess: print "%02x "%b,
The maxcpa is stored as an absolute value, since we may end up with positive or negative correlation. We only care about absolute value (e.g. there is a linear correlation), not sign. We also store only the maximum cpa across all points in the trace. Typically only a few points in the trace are correlating, and it's the maximum across the entire trace we are concerned with. This is done via this line of code:
maxcpa[kguess] = max(abs(cpaoutput[kguess]))
The argmax() function is used to find the maximum for all subkey candidates {0,1,2,...,255}, and which key candidate caused that maximum. The argmax() simply finds the indicie of the maximum value, and in this code the indicie corresponds to the subkey candidate.
When running this code, it's suggest to change the following:
for bnum in range(0, 16):
To only attack a single subkey, otherwise there is too much output:
for bnum in range(0, 1):
Assuming you've used the usual 2B 7E ... encryption key in your traces, running it would produce the following output:
Subkey 0, hyp = 00: 0.485067679972 Subkey 0, hyp = 01: 0.452597478584 ... bunch more lines ... Subkey 0, hyp = 29: 0.524796414777 Subkey 0, hyp = 2a: 0.429701324 Subkey 0, hyp = 2b: 0.971303850401 Subkey 0, hyp = 2c: 0.404439421891 Subkey 0, hyp = 2d: 0.429089006754 ... bunch more lines ... Subkey 0, hyp = ff: 0.449003229759 Best Key Guess: 2b 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Calculating The PGE
The Partial Guessing Entropy (PGE) is a useful metric of where the correct answer is ranked. This requires us to know the actual encryption key used during operation. If you've recorded traces with the regular ChipWhisperer system, this is stored alongside the traces & textin file. Check if you have a file called either _knownkey.npy or _keylist.npy. The knownkey file contains a single line, and the keylist contains a list of the encryption key corresponding with every input.
Certain attacks will use different keys during the acqusition period, meaning the keylist.npy file is required since there isn't a constant key. In our case we can load and print the key with:
>>> knownkey = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_knownkey.npy') >>> knownkey array([ 43, 126, 21, 22, 40, 174, 210, 166, 171, 247, 21, 136, 9, 207, 79, 60], dtype=uint8) >>> ["%02x "%k for k in knownkey] ['2b ', '7e ', '15 ', '16 ', '28 ', 'ae ', 'd2 ', 'a6 ', 'ab ', 'f7 ', '15 ', '88 ', '09 ', 'cf ', '4f ', '3c '] >>> "".join(["%02x "%k for k in knownkey]) '2b 7e 15 16 28 ae d2 a6 ab f7 15 88 09 cf 4f 3c '
Previously, we simply printed the maximum output for each subkey as follows:
#Find maximum value of key bestguess[bnum] = np.argmax(maxcpa)
To sort the list of CPA output's, we'll use the argsort() function from NumPy. This will output a list where the first element is the index of the lowest value, next element is the index of the next-highest element, etc. Because in our input list the maxcpa vector's indexes correspond to the key guess, this allows us to know where the keys are. We reverse that sorted list to put the first element as the maximum CPA output:
cparefs = np.argsort(maxcpa)[::-1]
Finally, the Partial Guessing Entropy is simply the location of the known correct key byte inside that array. We can find that with the .index() function:
print cparefs.index(0x2B)
Where the correct key should of course come from our knownkey variable instead of being hard-coded. Pulling it all together:
.... #Find maximum value of key bestguess[bnum] = np.argmax(maxcpa) cparefs = np.argsort(maxcpa)[::-1] #Find PGE pge[bnum] = list(cparefs).index(knownkey[bnum]) ....
Where at the beginning of the file we have to open the knownkey:
.... pt = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_textin.npy') knownkey = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_knownkey.npy') ....
Along with initilizing the pge[] array:
bestguess = [0]*16
pge = [0]*16
for bnum in range(0, 1):
....
Finally, you probably want to print the entire PGE:
.... print "Best Key Guess: ", for b in bestguess: print "%02x "%b, print "" print "PGE: ", for b in pge: print "%02d "%b,
When running the program, uncomment the #numtraces = 10 line and set the traces to something lower than the full file. You should see the PGE increase when you don't use all possible traces. You may also wish to comment out the printing of data for every guess, as this slows down the program.
Future Changes
The implementation of the correlation function runs as a loop over all traces. Ideally we'd like to implement this as a 'online' calculation; that is, we can add a trace in, observe the output, add another trace in, observe the output, etc. When generating plots of the Partial Guessing Entropy (PGE) vs. number of traces this is greatly preferred, since otherwise we need to run the loop many times!
We can use an alternate form of the correlation equation, which explicitly stores sums of the variables. This is easier to perform online calculation with, since when adding a new trace it's simple to update these sums. This form of the equation looks like:
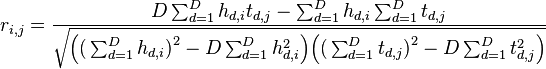
Complete Program
For reference here is the complete program. Before running you might want to make a few adjustments:
- Uncomment the
numtraces = 10line to use less traces - Comment out the
print "Subkey ..."line to avoid printing every value - Only run over a single subkey by adjusting the larger index in
for bnum in range(0, 16)
Here is the code:
import numpy as np
HW = [bin(n).count("1") for n in range(0,256)]
sbox=(
0x63,0x7c,0x77,0x7b,0xf2,0x6b,0x6f,0xc5,0x30,0x01,0x67,0x2b,0xfe,0xd7,0xab,0x76,
0xca,0x82,0xc9,0x7d,0xfa,0x59,0x47,0xf0,0xad,0xd4,0xa2,0xaf,0x9c,0xa4,0x72,0xc0,
0xb7,0xfd,0x93,0x26,0x36,0x3f,0xf7,0xcc,0x34,0xa5,0xe5,0xf1,0x71,0xd8,0x31,0x15,
0x04,0xc7,0x23,0xc3,0x18,0x96,0x05,0x9a,0x07,0x12,0x80,0xe2,0xeb,0x27,0xb2,0x75,
0x09,0x83,0x2c,0x1a,0x1b,0x6e,0x5a,0xa0,0x52,0x3b,0xd6,0xb3,0x29,0xe3,0x2f,0x84,
0x53,0xd1,0x00,0xed,0x20,0xfc,0xb1,0x5b,0x6a,0xcb,0xbe,0x39,0x4a,0x4c,0x58,0xcf,
0xd0,0xef,0xaa,0xfb,0x43,0x4d,0x33,0x85,0x45,0xf9,0x02,0x7f,0x50,0x3c,0x9f,0xa8,
0x51,0xa3,0x40,0x8f,0x92,0x9d,0x38,0xf5,0xbc,0xb6,0xda,0x21,0x10,0xff,0xf3,0xd2,
0xcd,0x0c,0x13,0xec,0x5f,0x97,0x44,0x17,0xc4,0xa7,0x7e,0x3d,0x64,0x5d,0x19,0x73,
0x60,0x81,0x4f,0xdc,0x22,0x2a,0x90,0x88,0x46,0xee,0xb8,0x14,0xde,0x5e,0x0b,0xdb,
0xe0,0x32,0x3a,0x0a,0x49,0x06,0x24,0x5c,0xc2,0xd3,0xac,0x62,0x91,0x95,0xe4,0x79,
0xe7,0xc8,0x37,0x6d,0x8d,0xd5,0x4e,0xa9,0x6c,0x56,0xf4,0xea,0x65,0x7a,0xae,0x08,
0xba,0x78,0x25,0x2e,0x1c,0xa6,0xb4,0xc6,0xe8,0xdd,0x74,0x1f,0x4b,0xbd,0x8b,0x8a,
0x70,0x3e,0xb5,0x66,0x48,0x03,0xf6,0x0e,0x61,0x35,0x57,0xb9,0x86,0xc1,0x1d,0x9e,
0xe1,0xf8,0x98,0x11,0x69,0xd9,0x8e,0x94,0x9b,0x1e,0x87,0xe9,0xce,0x55,0x28,0xdf,
0x8c,0xa1,0x89,0x0d,0xbf,0xe6,0x42,0x68,0x41,0x99,0x2d,0x0f,0xb0,0x54,0xbb,0x16)
def intermediate(pt, keyguess):
return sbox[pt ^ keyguess]
traces = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_traces.npy')
pt = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_textin.npy')
knownkey = np.load(r'C:\chipwhisperer\software\chipwhisperer\capture\default-data-dir\traces\2013.11.18-16.40.58_knownkey.npy')
numtraces = np.shape(traces)[0]-1
numpoint = np.shape(traces)[1]
#Use less than the maximum traces by setting numtraces to something
#numtraces = 10
#Set 16 to something lower (like 1) to only go through a single subkey
bestguess = [0]*16
pge = [256]*16
for bnum in range(0, 16):
cpaoutput = [0]*256
maxcpa = [0]*256
for kguess in range(0, 256):
print "Subkey %2d, hyp = %02x: "%(bnum, kguess),
#Initialize arrays & variables to zero
sumnum = np.zeros(numpoint)
sumden1 = np.zeros(numpoint)
sumden2 = np.zeros(numpoint)
hyp = np.zeros(numtraces)
for tnum in range(0, numtraces):
hyp[tnum] = HW[intermediate(pt[tnum][bnum], kguess)]
#Mean of hypothesis
meanh = np.mean(hyp, dtype=np.float64)
#Mean of all points in trace
meant = np.mean(traces, axis=0, dtype=np.float64)
#For each trace, do the following
for tnum in range(0, numtraces):
hdiff = (hyp[tnum] - meanh)
tdiff = traces[tnum,:] - meant
sumnum = sumnum + (hdiff*tdiff)
sumden1 = sumden1 + hdiff*hdiff
sumden2 = sumden2 + tdiff*tdiff
cpaoutput[kguess] = sumnum / np.sqrt( sumden1 * sumden2 )
maxcpa[kguess] = max(abs(cpaoutput[kguess]))
print maxcpa[kguess]
bestguess[bnum] = np.argmax(maxcpa)
cparefs = np.argsort(maxcpa)[::-1]
#Find PGE
pge[bnum] = list(cparefs).index(knownkey[bnum])
print "Best Key Guess: ",
for b in bestguess: print "%02x "%b,
print ""
print "PGE: ",
for b in pge: print "%02d "%b,
Conversion of Correlation Equation
The following shows the derivation of the online correlation equation from the original form:
